A question that has always bugged and fascinated me in reinforcement learning with language models is the duality of perspectives by which it can be viewed: as a long trajectory of token-level actions and with sparse final rewards, or as a single-action (bandit) environment where the entire answer is the action. This has repercussions on the way we do importance sampling, value modeling, KL penalties and - discussed in the following - reward baselines.
By accounting for token gradient correlation within the same sequence, we derive an optimal -weighted reward baseline. It naturally induces a stabilizing pessimistic bias recently shown to prevent training collapse in reasoning models in a theoretically justified manner. Experts can directly skip to the last sections.
The Setup
Consider the REINFORCE estimator of the policy gradient writing .
By the score identity, , so we can subtract any baseline that is independent of conditional on without introducing bias:
What is the optimal constant baseline ?
Deriving the Optimal Baseline
The optimal baseline minimizes the trace of the covariance with vector-valued.
Using bilinearity of covariance, we get:
Setting the derivative by to zero leads to because .
This makes intuitive sense: the variance-minimizing in is not the average of , but the average weighted by magnitude of .
By default, in reinforcement learning we make the assumption that and are independent, in which case the term simplifies to the known .
Token-level vs Sequence-level Actions
Let us now get back to the two complementary views of RL with LLMs in terms of its action space.
For token-level actions, we use the reward-to-go for (which in many setups simply happens to be the final end of sequence reward for all tokens) and is the gradient of the -th token. Using the default baseline then reduces to taking a mean-baseline at the token level (each token receives the same weight, not each sequence). In other words, if is the reward of the -th trajectory in GRPO and is its length, the baseline is Our team has ablated and used this choice in Code World Model.1
For sequence-level actions, the action is , so the gradient is the sum of token gradients Crucially, the gradient magnitude therefore depends on the correlation between the .
- If token gradients are uncorrelated and identically distributed, we have and .
- If token gradients are fully correlated, we have .
- In practice, we expect growth between these extreme cases: with . (This reminds of length penalties in decoding with early language models.)
The assumption of uncorrelated gradients again leads to the token-average baseline Generally, the assumption of -scaling suggests a -weighted mean baseline
Edit: After writing, I learned of the OPO paper2 that covers makes the argument for the token-mean baseline with the same derivation.
Initial Empirical Evidence
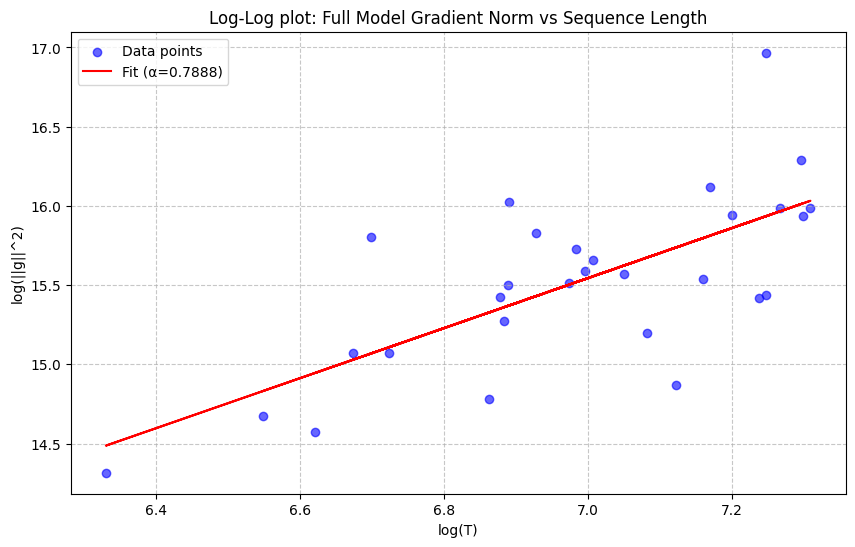
While out of big tech compute for now, let me present a quick measurement on the gradient scaling exponent with a small reasoning model.
We generate reasoning traces with DeepSeek-R1-Distill-Qwen-1.5B on 30 samples from the orca-math-word-problems-200k dataset, capping sequences at 1500 tokens. For each sample, we plot the reasoning trace length and the squared norm of the sequence gradient . We compute the scaling coefficient by linear regression in log-log space, where the slope equals .
Our measurement indicates for this small model. If the trend holds for larger datasets and models, an -scaling weighted baseline might perform better than the current default baselines, without requiring additional compute.
Context: Stability in RL via Baseline Shifts
In a recent paper by colleagues at FAIR,3 the authors find that adding a small negative bias to the GRPO sequence mean stabilizes training and prevents collapse. Concretely, they suggest setting where the average is the sequence-level mean baseline as in GRPO variance and is typically for 0-1-rewards. The result is pessimism about the policy, i.e. advantages are positive on average, shifting the loss slightly in the direction of positive sample SFT.
Here, I'd like to make a speculative, heuristic argument for how this might relate to -scaling.
The main finding of reasoning models is that over the course of training, longer sequence lengths are correlated with higher rewards (both go up over the course of training). However, at any given point in training, longer response lengths are correlated with lower rewards: These are reasoning traces that "time out" and do not converge on a satisfactory solution for submission.
Hence, since -scaling upweighs long sequences in the baseline average (more than the token-mean baseline and even more than the sequence-mean one), we expect the -scaling baseline to be lower than the default baselines. This amounts to a similar effect as adding negative as proposed in Asymmetric REINFORCE but now justified as a mechanism for optimal variance reduction.
Conclusion
Given the importance of training stability for truly scaling reinforcement learning post-training to pretraining levels of compute, we need to pay close attention to details in the reinforcement learning loss. The proposed gradient correlation-aware baseline is trivial to implement, empirically justified and could explain recent observations on training stability linked to baseline bias. Please go ahead and implement it and let me know of the results!
References
-
Copet, Jade, et al. "CWM: An open-weights LLM for research on code generation with world models." Arxiv 2025. ↩
-
Hao, Yaru, et al. "On-policy RL with optimal reward baseline." Arxiv 2025. ↩
-
Arnal, Charles, et al. "Asymmetric REINFORCE for off-policy reinforcement learning: Balancing positive and negative rewards." NeurIPS 2025. ↩